Pith — Smart prompt optimization that cuts your LLM costs
pithtoken.ai
Meet Pith. It optimizes your prompts before they hit OpenAI or Anthropic — saving you up to 30% on tokens. Zero code changes. Just swap your base URL.
About
Pith — Smart prompt optimization that cuts your LLM costs
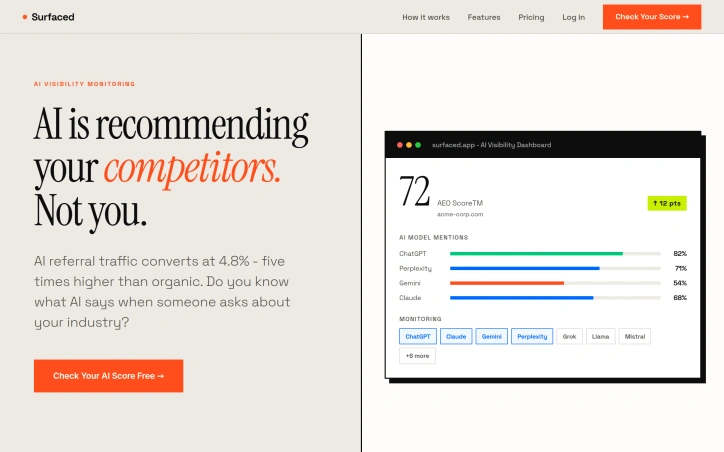
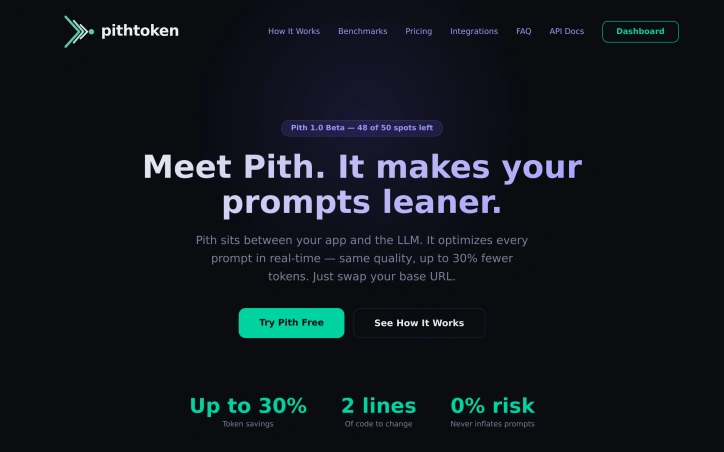
Developers can reduce their AI API costs by up to 30% by routing requests through Pith, a proxy service that optimizes prompts before they reach OpenAI or Anthropic. The service requires only two lines of code to integrate—users swap their base URL and API key, and Pith automatically optimizes every prompt in real-time while maintaining output quality.
Pith operates as a drop-in proxy that sits between applications and large language models. When a request comes through, the service analyzes and compresses the prompt to reduce token consumption. If optimization isn't possible without risking quality, Pith sends the original prompt unchanged, ensuring zero risk to existing workflows. The system learns continuously from every API call, building a pattern database that improves optimization performance over time across different industries and use cases.
The service tested its optimization across 50 diverse prompts spanning five categories. Results showed the free tier algorithm achieved 43.8% token reduction on verbose system prompts, outperforming GPT-4o-mini's 36.5%. The Pro tier combines algorithmic and AI-powered optimization for savings up to 35%. Already-concise prompts pass through unmodified.
Pith integrates with any tool or framework that supports the OpenAI API, including the Python and Node.js OpenAI SDKs, LangChain, LlamaIndex, REST clients, and autonomous AI agent frameworks like OpenClaw. Developers using code editors such as Cursor, Continue, and Aider can also configure Pith by setting a custom base URL in their tool configuration.
The pricing structure includes a free tier with no time limit, offering dashboard access, analytics, and up to 18% token savings using algorithmic optimization. Users receive $30 in free credits upon signup with no credit card required. The Pro tier adds LLM-powered deep analysis for up to 35% savings and early access to new features. Enterprise pricing operates on a revenue-share model where Pith charges only from the savings it generates, with longer commitments reducing both cost and revenue share percentage.
The service positions itself as particularly valuable for applications running autonomous AI agents, which typically consume tokens rapidly. Pith's optimization team consists of AI systems that operate continuously, analyzing patterns and refining algorithms without human schedule constraints.
Updated 3/30/2026
Ratings & reviews
No reviews yet. Be the first!
Site info
- Domain
- pithtoken.ai
- Status
- Active
- Listed since
- Mar 2026
- Domain age
- < 1 year
- SSL
- Secure
- Language
- en
- Built with
- Cloudflare
Related listings